
기존 이미지 검색은 CBIR(content based image retrieval) 기반의 이미지 검색으로 처리하였습니다. 오픈소스로는 lucene기반의 LIRE(Lucene Image REtrieval)이 있고 이걸 elasticsearch에 플러그인형식으로 올린 버전도 있습니다. elastic search blog 에도 포스팅이 옛날에 한 번 올라왔었죠~
이 방식도 histogram 이나 color layout등 여러 다양한 방식을 사용하지만 elasticsearch blog를 보시면 아시겠지만 비슷한 느낌의 이미지를 찾는다 보다는 비슷한 색상의 이미지를 찾는다 라는 느낌이 더 강합니다. 사람이 보기에 완전히 다른 이미지여도 색상만 얼추 비슷하면 결과로 뽑히는것이죠.
딥러닝을 공부하시는 분이라면 CNN(convolutional neural network)를 잘 아실것입니다. 이미지 관련하여 기계학습을 하는데 가장 널리 사용되는 알고리즘이고 특히 이미지 분류(Classification)에 매우 탁월한 성능을 보이는 알고리즘입니다. 대표적으로 구글의 inception (googlenet), ms의 resNet, mobilenet, VGG등이 있죠.
이번엔 분류가 아닌 이 CNN기반으로 이미지를 찾아보도록 하겠습니다.
준비물
- python
- tensorflow
- scikit-learn
- numpy
- matplotlib
우선 처음부터 모든 코드를 다 작성하는건 시간적으로나 지식적 한계로나 문제가 있기 떄문에 있는 코드를 가져다 쓸것입니다. tensorflow에는 tensorflow models라고 하는 별도의 서브 프로젝트가 존재하고 tensorflow를 이용해서 여러가지를 구현해놓은 소스 예제들이 있습니다. 우선 이 소스를 clone받습니다.
git clone https://github.com/tensorflow/models.git
cd models
그리고 공개된 많은 CNN 알고리즘중에 저는 Inception V3라고 하는 알고리즘을 사용할것입니다.
그리고 이미지 학습을 처음부터 하는것도 좋지만 학습은 많은 시간과 자원이 필요하므로 시간관계상 이미 열심히 잘 학습된 weight파일을 다운받습니다. inception 예제에서 쓰이는 weight 파일을 다운 받습니다.
# download the Inception v3 model
curl -O http://download.tensorflow.org/models/image/imagenet/inception-v3-2016-03-01.tar.gz
tar xzf inception-v3-2016-03-01.tar.gz
그리고 이미지 검색을 만들 이미지 데이터를 다운 받겠습니다. 학습 이미지는 아무거나 상관없지만 공개된 이미지 데이터셋인 옥스포드 pet 데이터셋을 받겠습니다. The Oxford-IIIT Pet Dataset사이트에 접속해서 Downloads항목의 dataset을 다운 받습니다. 다운받으면 여러 종류의 개와 고양이 이미지들이 약 7천여종정도 있을것입니다. 왜 이 이미지셋을 선택했냐면
귀.여.우.니.깐뭐.. 아무튼, 준비물은 된거 같으니 작업을 해보도록 하겠습니다.
설명
여기서 inception v3의 알고리즘을 모두 설명하긴 어렵기도 하고 구글링 해보면 이미 다른 블로그에 자세히 설명이 나오기도 해서 자세한 설명은 생략하고 간단히만 말하자면
- n개의 input 이미지를 input으로 준비
- 이미지를 (n, 299, 299 3)의 배열로 변환
- 여러과정을 거쳐 (n, 2048)의 배열로 변환
- fully connected로 m개의 class로 분류
- softmax로 m개의class의 합이 1이 나오게 변경
- argmax로 가장 높은 수치를 가진 class를 찾음
이정도 과정을 거치는데 우리가 할껀 classification이 아니니까 4번까지 과정만 사용하고 나머지는 하지 않을거에요.
우선 사용할 library를 import 합니다.
import tensorflow as tf
import numpy as np
from inception.data import build_image_data
from inception import image_processing
from inception import inception_model as inception
from os import listdir
from os.path import isfile, join
아까 다운받은 models 프로젝트의 소스들도 일부 사용할껀데 만일 import가 안되면 폴더안에 init.py를 만들어 package로 동작하게 만들어주세요.
checkpoint_dir = "/data/dev/inception-v3"
batch_size = 100
checkpoint_dir은 아까 다운받았던 weight파일이 있는 주소고 batch_size는 한꺼번에 몇개의 이미지를 프로세싱할건지의 수치입니다.
my_image_path = "/data/dev/pets/images/"
img_file_list = [f for f in listdir(my_image_path) if (f.rfind('jpg') > -1)]
file_size = len(img_file_list)
my_image_path는 다운받은 옥스포드 펫 이미지의 경로이고 이 폴더를 스캔해서 list로 만들어줍니다.
def inference_on_multi_image():
print("total image size {} ".format(file_size) )
total_batch_size = file_size / batch_size + 1
logit_list = []
for n in xrange(total_batch_size):
print("step :{} / {}".format(n + 1, total_batch_size))
mini_batch = img_file_list[n * batch_size: (n + 1) * batch_size]
mini_adarr = np.ndarray(shape=(0, 299,299,3))
with tf.Graph().as_default():
num_classes = 1001 # (logit size)
coder = build_image_data.ImageCoder()
for i, image in enumerate(mini_batch):
image_buffer, _, _ = build_image_data._process_image(my_image_path + image, coder)
image = image_processing.image_preprocessing(image_buffer, 0, False) # image -> (299, 299, 3)
image = tf.expand_dims(image, 0) # (299, 299,3) -> (1, 299, 299, 3)
mini_adarr = tf.concat([mini_adarr, image], 0)
logits, _ = inception.inference(mini_adarr, num_classes, for_training=False, restore_logits=True)
saver = tf.train.Saver()
with tf.Session() as tf_session:
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
if os.path.isabs(ckpt.model_checkpoint_path):
# Restores from checkpoint with absolute path.
saver.restore(tf_session, ckpt.model_checkpoint_path)
else:
# Restores from checkpoint with relative path.
saver.restore(tf_session, os.path.join(checkpoint_dir,
ckpt.model_checkpoint_path))
l = tf_session.run([logits])
for row in l[0]:
logit_list.append(row)
return logit_list
logit_list = inference_on_multi_image()
소스가 좀 최적화가 안돼있긴 한데 그래도 대충 돌아는 갑니다(무책임). 아까 폴더를 스캔해서 읽어들인 펫이미지들을 preprocessing하여 배열로 만든다음에 inception.inference 를 태워 데이터를 받아옵니다. 중간 num_classes 변수는 원래 몇개의 class로 나눌것인가에 대한 변수이고 최종 몇개의 size를 가진 array가 output으로 나오는지를 결정하며, 기본적으로 imagenet챌린지가 1000개의 카테고리로 분류를 하기 때문에 1000을 설정하고 보통 inception v3에서 1개를 더미 클래스로 사용하기 때문에 1001로 설정하였습니다. 사실 현재 작업은 분류를 위한것은 아니기 때문에 굳이 1001이 아니여도 상관없습니다. 큰 의미 가지지 않으셔도 됩니다.
모든 이미지를 다 데이터를 만들었다면 이 데이터를 nearest neighbor알고리즘을 통해 거리를 계산합니다. 이미 이 알고리즘이 짜여져 있는 scikit-learn을 통해 학습 하겠습니다.
from sklearn.neighbors import NearestNeighbors
knn = NearestNeighbors(n_neighbors=10)
knn.fit(logit_list)
만들었으면 이제 이미지로 실제 제대로 동작하나 테스트 해봐야겠죠. 우선 함수를 두개 만들고요
def show_image(predictions):
for i in predictions:
print_image(my_image_path + img_file_list[i])
def print_image(path):
plt.figure()
im = mpimg.imread(path)
plt.imshow(im)
이미지 목록중 아무거나 꺼내와봅시다. 999번째 이미지로 테스트 해봅니다. 이렇게 생긴 비글 이미지네요.

999번째 인덱스의 이미지랑 근접한 있는 이웃들을 찾아보겠습니다.
predict = knn.kneighbors(logit_list[999], return_distance=False)
print predict
## [[999 824 939 908 951 971 893 954 874 990 982]]
숫자가 해당하는 데이터의 index번호라고 보시면 됩니다. 제대로 찾아졌는지 이 해당 index의 수치의 이미지를 출력해보겠습니다.
show_image(predict[0])
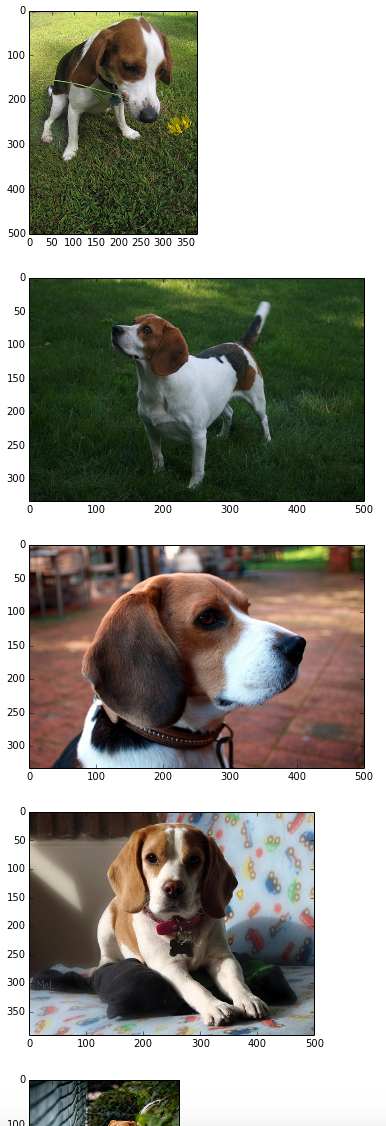
여러 비글 이미지가 찾아졌습니다! 여러 다양한 품종의 개와 고양이가 다같이 데이터를 넣었으나 가장 유사한 이미지로 비글들만 찾아졌습니다. 그리고 색상에 영향을 많이 받은것 같았던 CBIR과는 다르게 배경이나 모양이 많이 다르더라도 이미지의 feature를 제대로 찾아준다는 느낌을 받을 수 있습니다.
그럼 혹시 이게 잘 구분된 학습시킨 이미지라 잘나오는게 아닌가 생각할 수 있습니다. 아무 고양이 이미지나 구해서 넣어보겠습니다.

고양이가 이미지내에 있긴 하지만 고양이 사이즈가 작고 사료등의 이미지랑 같이 섞여있습니다. 결과는 그래도 고양이 이미지를 잘 찾아왔습니다.

다른 고양이 이미지도 역시 잘 찾습니다.
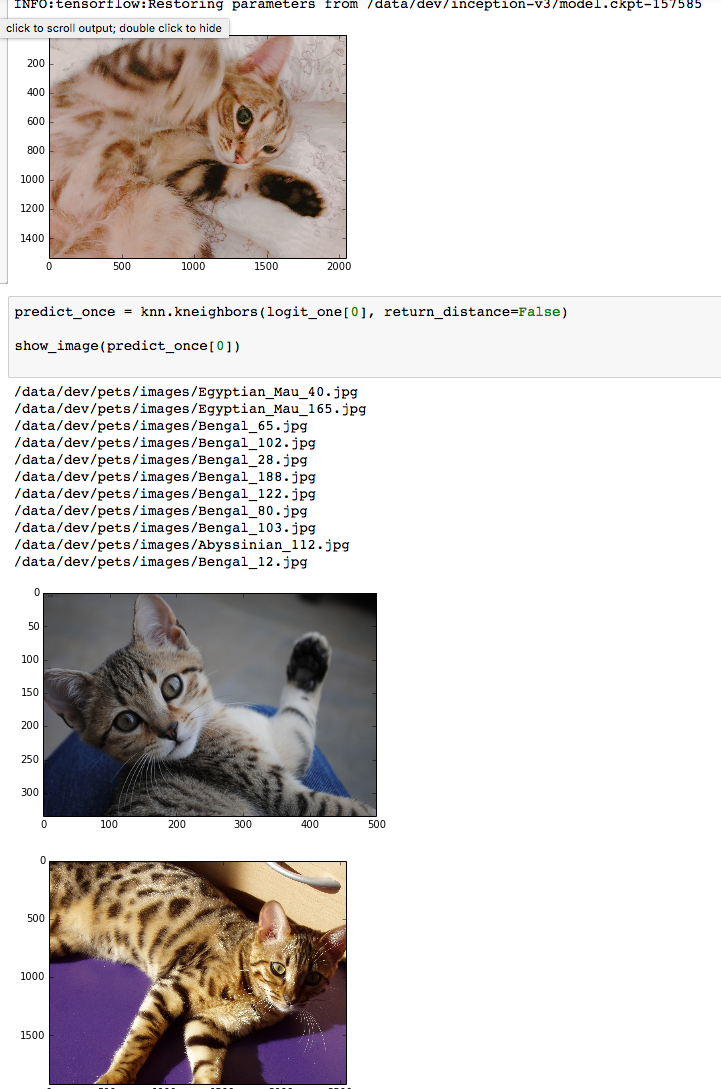
실제로 해당 소스를 돌린 notebook은 깃헙링크에서 확인 가능합니다.
마치며
물론 아직은 그대로 production레벨에 쓰기는 당연히 많이 부족합니다. 성능 문제도 있고 지금처럼 잘 분류된 펫이미지가 아닌 무작위의 이미지라면 어떻게 될지 모르겠네요.
좀더 로직을 보안하고 여기에 추가로 결과를 좀 더 보정할 수 있는 알고리즘을 더 섞어보다면 재미있는 결과가 나올것 같습니다.
